Paul Sheriff, Michael Krasowski
PDSA, Inc.
2003년 12월
요약 : Microsoft Visual SourceSafe를 사용하여 ASP.NET 프로젝트를 관리하는 전체 프로세스를 안내합니다(17페이지/인쇄 페이지 기준).
적용 대상:
Microsoft ASP.NET
Microsoft Visual SourceSafe
목차
.gif) 소스 코드 컨트롤을 사용해야 하는 이유
소스 코드 컨트롤을 사용해야 하는 이유
격리 모드와 비격리 모드 비교
SourceSafe 데이터베이스 설정
VSS에 ASP.NET 솔루션 추가
VSS로 파일 조작
파일 기록 추적
소프트웨어 버전에 레이블 사용
Visual Studio .NET에서 솔루션 가져오기
결론
일부 개발자들은 소스 코드 컨트롤을 반드시 사용해야 하지만 매우 번거로운 것으로 생각합니다. 하지만 소스 코드 컨트롤은 소프트웨어 개발 프로세스를 지원하는 안전한 업무 관례입니다. 이 문서에서는 실제로 Microsoft Visual SourceSafe를 소스 코드 컨트롤 메커니즘으로 유용하게 사용하는 단계별 방법을 보여 줍니다. 새 SourceSafe 데이터베이스를 만드는 방법, 파일을 체크 인하고 체크 아웃하는 방법, 레이블을 사용하여 릴리스를 만드는 방법을 볼 수 있습니다.
소스 코드 컨트롤을 사용해야 하는 이유
단순하게 말하자면 VSS(Visual SourceSafe) 같은 SCM(Software Configuration Management) 제품은 프로젝트를 구성하는 문서의 중앙 라이브러리(데이터베이스)입니다. Visual SourceSafe에는 프로젝트 계획, 사양 설명서, 데이터베이스 개체, 소스 코드 등의 비트 스트림과 프로젝트의 기타 모든 항목을 저장할 수 있습니다. 최상의 방법은 소스 코드뿐만 아니라 모든 프로젝트 항목을 Visual SourceSafe 데이터베이스에 포함시키는 것입니다. 그러면 액세스 및 팀 구성원 간 공유가 용이해지며, 무엇보다도 버전 제어가 용이해집니다.
여느 라이브러리에서처럼 사용할 파일을 "체크 아웃"하는 기능이 필요합니다. 사용자는 파일을 체크 아웃한 후 편집할 수 있습니다. 일반적으로 한 번에 한 명의 사용자만 파일을 체크 아웃하여 편집할 수 있습니다. 언제나 한 명의 사용자만 파일을 체크 아웃할 수 있도록 하는 것이 가장 좋습니다. 간혹, 같은 파일을 여러 사용자가 체크 아웃할 수 있도록 할 것을 권장하는 Visual SourceSafe 사용 시나리오를 소개하는 백서도 있습니다. 이러한 백서에서는 나중에 모든 변경 사항을 함께 병합할 수 있도록 할 것을 권장합니다. 그러나 VSS에 기본 제공되는 도구를 사용하면 쉽게 병합할 수 있을 것 같지만 실제로는 여러 가지 단점이 있습니다. 항목을 다시 체크 인하는 데 시간이 더 오래 걸리고, 병합 프로세스에서 충돌을 수동으로 점검해야 할 경우가 발생할 수 있으며, 데이터베이스, Microsoft Word 문서 등의 이진 항목에는 대개 사용할 수 없습니다. 또한 업데이트된 항목과 업데이트한 사람 및 시간에 대한 정확한 기록을 반영하지 못하는 경우가 있습니다.
VSS에서는 라이브러리 관리자가 액세스 제어를 정의할 수 있습니다. 사용자에게는 액세스 ID 및 암호, 그리고 액세스 권한이 주어집니다. 액세스 권한은 읽기 또는 읽기/쓰기 기능처럼 단순할 수도 있고, 기능 권한과 같이 복잡할 수도 있습니다. 예를 들어 파일을 삭제하는 기능도 하나의 기능 권한입니다.
모든 개별 파일(소스 코드, 프로젝트 계획, 요구 사항 등)에 대해 각각의 파일 주기 동안 어떠한 변화가 있었는지 파악하는 것은 매우 중요합니다. VSS는 파일을 만든 시간과 만든 사람, 해당 파일에 대한 각 수정, 해당 파일에 대한 메모 또는 주석, 그리고 해당 문서의 주기를 추적하는 데 도움이 되는 기타 정보 등 모든 작업 기록을 보관합니다.
위에서 언급한 VSS의 기능과 그 외 여러 기능을 통해 잘 관리된 구조적인 방식으로 개발, 빌드 및 유지 관리 프로세스를 효율적으로 관리할 수 있습니다. 이 외에도, VSS를 사용하여 소프트웨어 개발의 생산성을 높일 수 있는 이유에는 여러 가지가 있습니다.
격리 모드와 비격리 모드 비교
팀 환경에서 웹 응용 프로그램을 개발할 경우 두 가지 모델 중에서 하나를 선택할 수 있습니다. 첫 번째 방식인 비격리 모델에서는 모든 개발자가 중앙 서버에서 모든 파일을 만들고 수정합니다. 비격리 개발 모델에서는 중앙 공유 컴퓨터에서 하나의 Microsoft IIS(Internet Information Services) 서버를 사용해야 하며, 응용 프로그램의 모든 파일이 해당 서버의 가상 디렉터리에 상주해야 합니다. 모든 개발자가 VSS에서 파일을 체크 아웃하며, 체크 아웃된 파일은 중앙 IIS 서버의 가상 디렉터리로 이동합니다.
두 번째 웹 개발 방식인 격리 모델에서는 각 개발자가 자신의 개발 컴퓨터에서 실행 중인 IIS 안에 가상 디렉터리를 만듭니다. 격리 방식에서는 각 개발자가 중앙 VSS 데이터베이스에서 로컬 컴퓨터로 파일을 가져오거나 체크 아웃합니다. 개발자는 로컬 컴퓨터에서 모든 내용을 편집, 디버그 및 테스트하고 모든 내용이 정상적으로 작동하면 파일을 중앙 위치로 다시 체크 인할 수 있습니다. 체크 인된 파일은 다른 개발자가 가져올 수 있습니다.
두 가지 개발 유형 모두 장단점이 있습니다. 각각의 장점과 단점을 살펴보겠습니다.
비격리 개발의 장점
비격리 개발의 단점
-
다른 개발자의 작업에 의도하지 않은 영향을 미치기 쉽습니다.
-
한 개발자가 디버깅을 위해 응용 프로그램을 실행하는 동안에는 프로세스가 잠기므로 다른 개발자들이 응용 프로그램을 디버그할 수 없습니다.
-
여러 개발자가 같은 파일을 작업하는 경우에는 마지막에 체크 인한 파일이 최종 파일이 됩니다.
-
소스 제어 기능이 제한되어 있습니다.
-
한 개발자가 일부 코드를 수정하여 해당 코드가 작동하지 않을 경우 다른 모든 개발자가 더 이상 프로젝트의 해당 부분을 실행할 수 없게 됩니다.
격리 개발의 장점
-
다른 개발자를 부주의하게 방해하지 않고 응용 프로그램을 개발 및 디버그할 수 있습니다.
-
다른 개발자에게 영향을 미치지 않고 로컬에서 변경 내용을 테스트할 수 있습니다.
-
소스 코드 컨트롤에 대한 지원이 뛰어납니다.
-
개발자는 네트워크에 연결하지 않아도 프로젝트를 다른 컴퓨터로 이동하거나 가지고 다니면서 사용자를 표시할 수 있습니다.
격리 개발의 단점
선택할 모델
격리 개발 모델을 사용할 것을 권장합니다. 물론 이를 위해서는 각 사용자의 컴퓨터에 IIS가 있어야 하므로 일부 조직에서는 제약이 따를 수 있습니다. 하지만 격리 모델은 가장 유연한 소스 코드 컨트롤을 위한 최상의 모델입니다.
격리 개발을 위한 Visual Studio .NET 설정
격리 모델을 사용할 수 있도록 Microsoft Visual Studio .NET에서 올바른 옵션을 설정했는지 확인하십시오. Visual Studio .NET에서 도구 | 옵션 탭으로 이동하고 Microsoft FrontPage Extensions 옵션이 아닌 파일공유를 클릭합니다. FrontPage Extensions 옵션은 모든 파일이 중앙 서버에 위치한 비격리 방식을 사용할 경우 선택하는 옵션입니다.
SourceSafe 데이터베이스 설정
지금까지는 Visual SourceSafe의 개요 및 사용 이점에 대해 알아보았습니다. 이제 Visual SourceSafe를 시작하는 방법을 살펴보겠습니다. 첫 번째 단계는 중앙 VSS 데이터베이스의 위치를 찾는 것입니다. 이 데이터베이스는 엄밀한 의미에서 데이터베이스라기 보다는 하드 드라이브의 폴더입니다. 이 폴더는 모든 개발자가 찾을 수 있는 네트워크 공유에 배치되어야 합니다. 개발자가 한 명뿐일 경우에는 개발자의 로컬 하드 드라이브에 배치할 수도 있습니다.
VSS 관리 도구를 아직 설치하지 않았으면 VSS CD에서 설치합니다. 사용자 지정 설치를 통해 이 옵션을 선택해야 합니다. CDD에서는 일반적으로 ACMBoot.exe를 실행하여 관리 도구를 설치합니다. 사용자 지정 설치 옵션에서 Administrative Programs 및 Create SourceSafe Database 옵션을 선택해야 합니다.
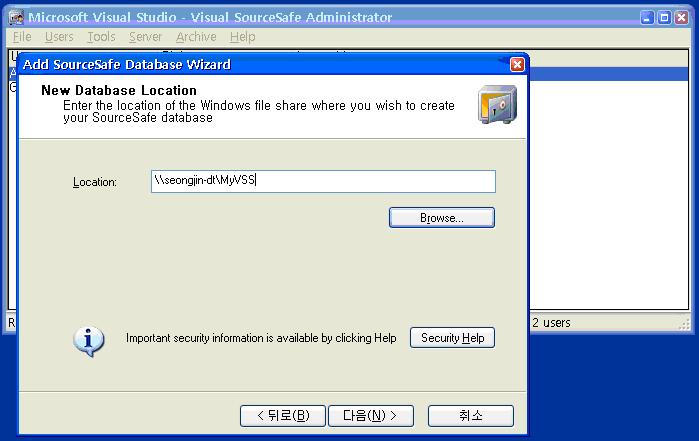
관리 프로그램을 설치한 후에는 시작 메뉴로 이동하여 프로그램 | Microsoft Visual SourceSafe | Visual SourceSafe 6.0 Admin을 클릭합니다. 새로 시작되는 인터페이스에서 Tools | Create Database...를 클릭합니다 . 그러면 그림 1과 같은 대화 상자가 표시됩니다. 이 새 SourceSafe 데이터베이스를 만들 위치를 "D:\MyVSSDB" 또는 \\SharedDrive\MyVSSDB와 같이 입력합니다.
.gif)
그림 1. 모든 SourceSafe 파일에 사용할 공유 폴더의 위치를 지정합니다.
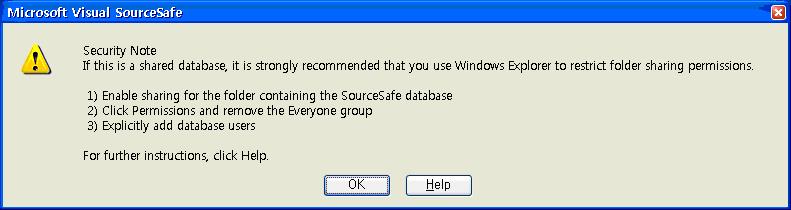
데이터베이스를 만들고 나면 그림 2와 같은 대화 상자가 표시됩니다. 이 대화 상자는 이 SourceSafe 데이터베이스를 만들 때 만들어지는 Admin 사용자에 관련 암호가 없다는 것을 나타내는 경고일 뿐입니다. Admin 사용자를 클릭하고 메뉴에서 Users | Change Password...를 클릭하여 Admin 사용자에 암호를 할당하십시오.
.gif)
그림 2. Admin 사용자에 암호를 할당하여 관리 도구를 보안합니다.
데이터베이스를 만들고 나면 Visual SourceSafe Administrator 도구(그림 3)가 나타납니다. 이 도구에서는 한 번에 하나의 VSS 데이터베이스에만 연결할 수 있습니다. 이 데이터베이스에서 파일을 체크 아웃하고 체크 인할 수 있도록 할 모든 사용자를 이 데이터베이스 안에서 만들어야 합니다. 만드는 각 데이터베이스마다 해당 사용자를 추가해야 합니다. 이 기능은 설정된 사용자만 이 데이터베이스를 사용할 수 있도록 하므로 유용합니다. 그러나 모든 사용자에게 액세스를 허용할 VSS 데이터베이스가 여러 개 있는 경우 각 데이터베이스에서 각 사용자를 개별적으로 설정해야 합니다.
.gif)
그림 3. Administrator 도구에서는 새 사용자를 만들고, 데이터베이스를 만들고, 데이터베이스를 잠그며, SourceSafe 에 대한 기타 시스템 관리 기능을 수행할 수 있습니다.
이제 이 데이터베이스에 자기 자신을 새 사용자로 추가해야 합니다. SourceSafe에서 도메인 로그온 ID(도메인 이름 제외)를 사용자 이름으로 사용하고 있는지 확인하십시오. SourceSafe는 아무런 메시지를 표시하지 않고 도메인 로그온 ID를 사용하여 로그온을 시도합니다. 이 VSS 데이터베이스에 암호를 할당한 경우에는 해당 암호가 도메인 암호와 일치하는지도 확인하십시오.
이 새 데이터베이스의 위치를 기억해야 합니다. 데이터베이스에 사용자를 도메인 이름과 함께 추가한 후에는 사용자가 VSS 클라이언트 유틸리티를 처음 설정할 때 데이터베이스를 찾을 수 있도록 모든 사용자에게 데이터베이스 위치를 알려야 합니다.
VSS에 ASP.NET 솔루션 추가
새로 만든 VSS 데이터베이스에 프로젝트 및 프로젝트 항목을 추가할 수 있습니다. 두 가지 방법을 통해 이 VSS 데이터베이스를 조작할 수 있습니다. 즉, "다른 프로젝트 항목"을 데이터베이스에 추가하는 데 유용한 VSS Explorer 도구를 사용하거나 Visual Studio .NET 내에서 VSS를 사용할 수 있습니다. 사실 VSS에 새 프로젝트를 추가하는 경우에는 Visual Studio .NET을 사용하여 추가하는 것이 좋습니다. Visual Studio .NET 인터페이스를 사용하면 .SLN 파일에 몇 가지 바인딩 정보가 추가되므로 개발자가 VSS에서 솔루션을 가져올 때 VSS에 자동으로 연결될 수 있습니다.
참고 이 문서의 예제에서는 ASP.NET (US) 사이트에서 다운로드할 수 있는 Microsoft ASP.NET Portal Starter Kit을 사용하여 파일을 체크 인하고 체크 아웃했습니다. 원하는 다른 프로젝트를 사용할 수도 있습니다.
ASP.NET Portal Starter Kit을 다운로드하여 설치했다고 가정하고 VSS에 이 솔루션을 추가하는 방법을 설명하겠습니다. Visual Studio .NET에서 솔루션을 열고 그림 4와 같이 메뉴에서 File | Source Control | Add Solution to Source Control...을 선택합니다.
.gif)
그림 4. Visual Studio .NET 에서 기본 제공하는 메뉴를 사용하여 솔루션을 SourceSafe 에 추가합니다.
이 메뉴 항목을 선택한 후에는 그림 5와 같은 대화 상자가 표시될 것입니다. 격리 개발 모드를 사용하는 경우 이 대화 상자는 FrontPage Server Extensions 대신 일반 파일 URL을 사용하여 모든 파일을 참조한다는 의미일 뿐입니다. Don't' show this dialog box again (Always allow addition of Web projects using File Share access to source control) 확인란을 클릭하고 Continue를 클릭하십시오.
.gif)
그림 5. FrontPage Server Extensions 에서 파일 공유 액세스 사용으로 전환
이제 VSS 데이터베이스를 설정할 때 만든 로그온 ID와 암호(그림 6 참고)를 입력할 차례입니다. 설정한 ID(예: JohnD)와 암호를 입력합니다. 그런 다음 Browse...를 클릭하여 VSS 데이터베이스를 만든 특정 폴더를 찾습니다. 작업을 마쳤으면 OK를 클릭합니다.
.gif)
그림 6. VSS 로그온
데이터베이스에서 만들 프로젝트 이름을 입력하는 대화 상자가 나타납니다. 첫 번째 대화 상자인 "Add to SourceSafe Project"(그림 7)는 솔루션 파일이 있는 Visual Studio .NET 프로젝트를 나타냅니다. 그림의 "ASP.NET Portal Starter Kit (VBVS)"와 같이 이 프로젝트의 이름을 입력합니다.
.gif)
그림 7. 본인이나 다른 개발자가 나중에 쉽게 찾을 수 있도록 프로젝트에 이름을 지정합니다.
솔루션에 있는 모든 개별 Visual Studio .NET 프로젝트를 입력하는 대화 상자가 나타납니다. 그림 8과 같이 VSS는 각 Visual Studio .NET 프로젝트 이름을 "Add to SourceSafe Project" 대화 상자의 입력란에 자동으로 추가합니다. 이 경우 두 번째로 입력되는 내용은 PortalVBVS입니다. "ASP.NET Portal Starter Kit (VBVS)" 폴더를 클릭하여 이 프로젝트를 이 솔루션 아래에 배치해야 합니다.
.gif)
그림 8. 각각의 새 프로젝트를 VSS 에 개별적으로 추가합니다.
솔루션 파일이 프로젝트와 동일한 폴더에 있다는 경고 메시지가 표시됩니다. 의도적으로 같은 폴더에 배치한 것이므로 확인란을 클릭하여 계속 진행합니다. 그림 9와 같은 대화 상자가 나타날 수도 있고 나타나지 않을 수도 있습니다. 이 대화 상자가 나타나면 확인란을 선택하고 OK를 클릭합니다. 이 경우 다른 항목은 프로젝트 파일의 일부분이 아닌 폴더에 있기 때문에 나중에 VSS Explorer 도구를 통해 수동으로 추가해야 합니다. 폴더 안에 있지만 프로젝트 파일로 새로 지정된 문서 또는 .SQL 파일이 이러한 항목에 해당할 수도 있습니다.
.gif)
그림 9. 프로젝트 파일에서 참조하지 않는 추가 파일이나 폴더가 있으면 VSS 에서 이를 사용자에게 알립니다 .
솔루션과 프로젝트를 SourceSafe 제어 아래에 배치하고 나면 Visual Studio .NET이 그림 10과 같이 특수 아이콘을 사용하여 파일이 잠겼는지 아니면 체크 인되었는지 표시합니다. 소스 코드 컨트롤 아래의 각 파일 옆에는 자물쇠 아이콘이 표시됩니다. 자신이 체크 아웃한 파일 옆에는 확인 표시가 나타나고, 다른 사용자가 체크 아웃한 파일에는 원형 아이콘이 나타납니다.
.gif)
그림 10. Visual Studio .NET 은 소스 코드 컨트롤 아래에 각 파일의 상태를 표시합니다 .
VSS 데이터베이스 내의 전체 프로젝트를 보려면 운영 체제 메뉴에서 시작 | 모든프로그램| Microsoft Visual SourceSafe| Microsoft Visual SourceSafe 6.0을 선택하십시오. 다시 로그온해야 할 수도 있습니다. 로그온 이름과 암호를 입력하십시오. VSS Explorer(그림 11 참고)를 처음 실행하는 경우 데이터베이스를 만든 폴더를 탐색하여 VSS 데이터베이스도 찾아야 합니다.
.gif)
그림 11. Visual SourceSafe Explorer 에서는 전체 프로젝트 및 소스 코드 컨트롤 아래에 배치된 모든 파일을 볼 수 있습니다.
VSS로 파일 조작
프로젝트 파일을 VSS 데이터베이스에 배치하고 나면 프로젝트의 모든 파일이 디스크에서 읽기 전용으로 설정됩니다. 체크 아웃되지 않은 파일로 솔루션을 실행할 수도 있습니다. 그러나 Visual Studio .NET 내에서 파일을 작업하려면 체크 아웃해야 합니다. 현재의 작업과 비교하면 한 단계가 추가된 것이지만 대신 이전 버전으로 다시 돌아갈 수 있으며 다른 개발자가 수정 중인 파일을 사용자가 동시에 수정할 수 없도록 합니다.
파일 체크 아웃
파일 작업을 위해 체크 아웃해야 할 때는 Solution Explorer 창에서 해당 파일을 마우스 오른쪽 단추로 클릭하고 상황에 맞는 메뉴에서 Check Out...을 클릭하기만 하면 됩니다. 예를 들어 Portal Starter Kit에서 Default.aspx 파일을 클릭하고 마우스 오른쪽 단추를 클릭한 다음 Check Out...을 클릭합니다. 그림 12와 같은 대화 상자가 나타납니다. Check Out 단추를 클릭하면 .ASPX 파일뿐만 아니라 .ASPX.resx 및 .ASPX.VB 파일도 체크 아웃됩니다. 이제 해당 파일을 작업할 수 있으며 다른 사용자에게 파일이 체크 아웃된 것으로 표시됩니다.
.gif)
그림 12. Check Out 대화 상자에서는 프로젝트 파일을 하나 또는 여러 개 가져와서 하드 드라이브에 쓸 수 있는 상태로 설정할 수 있습니다 .
파일 체크 인
체크 아웃한 파일에서 원하는 내용을 모두 수정한 후에는 SourceSafe에 다시 체크 인해야 합니다. 파일을 체크 인할 경우 두 가지 사항을 염두에 두어야 합니다. 첫째, 프로젝트의 페이지 또는 클래스에서 변경한 내용이 컴파일되는지 확인해야 합니다. 그렇지 않으면 SourceSafe 데이터베이스에서 최신 변경 사항을 가져오는 다른 개발자의 프로젝트에서 오류가 발생하는 곤란한 상황이 발생합니다. 둘째, 매일 일과가 끝나면 파일을 모두 체크 인해야 합니다. 그러면 파일이 단지 하드 드라이브에 저장되는 것이 아니라 다른 위치에 백업됩니다. 따라서 하드 드라이브에 문제가 발생할 경우에도 변경한 내용을 모두 보존할 수 있습니다. 일과 후에도 소스 코드가 아직 컴파일되지 않은 경우에는 문제가 되는 코드에 주석을 달고 체크 인하면 됩니다.
최신 버전 가져오기
팀 환경에서 작업하는 경우 프로젝트 내에서 다른 파일을 수정하는 다른 개발자도 있습니다. 특정 시점에서는 VSS 데이터베이스에 있는 모든 최신 변경 사항을 프로젝트와 동기화할 수 있습니다. 그러기 위해서는 Visual Studio .NET Solution Explorer 창에서 프로젝트를 클릭하고 마우스 오른쪽 단추를 클릭한 다음 Get Latest Version (Recursive)를 클릭합니다. 그러면 VSS 데이터베이스로 이동하여 변경된 모든 파일을 검색하고 해당 파일을 프로젝트로 가져옵니다. 이제 로컬 컴퓨터에서 프로젝트를 실행하고 나면 다른 개발자가 변경한 내용을 모두 볼 수 있습니다.
파일 기록 추적
특정 시점에서 개발 팀은 "빌드", "버전" 또는 "릴리스"를 만들 수도 있습니다. VSS는 버전 번호를 사용하여 파일 및 프로젝트에 대한 모든 변경 사항을 추적합니다. 따라서 파일 또는 프로젝트의 모든 버전을 검색할 수 있습니다. VSS는 내부 버전 번호, 날짜 및 사용자 정의 레이블의 세 가지 항목을 기준으로 이전 버전을 추적합니다. 버전을 자체적으로 지정하는 경우에는 VSS에서 할당한 내부 버전 번호가 아니라 사용자 정의 레이블을 사용합니다.
버전 번호
VSS는 체크 인된 각 파일에 대해 내부 버전 번호를 유지합니다. 파일을 체크 아웃하고 변경한 다음 VSS에 다시 체크 인할 때마다 해당 파일 버전에 대한 새 번호가 만들어집니다. VSS에서 History 대화 상자를 사용하여 파일의 전체 기록을 볼 수 있습니다. History 대화 상자는 Visual Studio .NET 또는 VSS Explorer 도구를 통해 볼 수 있습니다.
Visual Studio .NET에서 기록을 볼 파일(예: default.aspx)을 클릭한 다음 Visual Studio .NET 메뉴 시스템에서 File | Source Code Control | History를 클릭합니다. 그러면 그림 13과 같은 대화 상자가 나타납니다. default.aspx 파일을 아직 변경하지 않은 경우에는 첫 번째 버전 이외의 다른 버전이 없습니다.
VSS Explorer 도구를 사용하는 경우 Explorer에서 특정 파일을 찾아서 마우스 오른쪽 단추로 클릭한 다음 Show History... 메뉴 항목을 클릭하여 동일한 대화 상자를 표시합니다.
.gif)
그림 13. VSS Explorer 에 파일의 전체 기록이 표시됩니다.
참고 내부 VSS 버전 번호는 단순히 참조용이며 빌드 또는 버전 번호와 직접적인 관련이 없습니다. 빌드 또는 버전 번호에는 레이블(아래 참고)을 사용합니다.
소프트웨어 버전에 레이블 사용
SourceSafe에서 파일에 할당하는 내부 버전 번호를 사용하는 대신 소프트웨어 릴리스를 정의하는 자신만의 코드 집합용 "레이블"을 만들 수도 있습니다. 릴리스는 첫 번째 베타 버전, 제품의 첫 번째 버전, 증분 릴리스, 제품의 두 번째 또는 세 번째 릴리스일 수 있습니다.
각 파일에는 자체 내부 버전 번호가 지정되며, 파일 수정 빈도에 따라 이 번호는 전체 프로젝트에서 전혀 일치하지 않게 됩니다. 따라서 내부 버전 번호 대신 자신만의 레이블을 전체 프로젝트에 적용하여 이 레이블을 만든 특정 시점에서 체크 인된 모든 파일을 식별할 수 있습니다.
레이블(최대 31자)을 만들 때 "1.0," "2.01b," "Final Beta" 또는 "Approved for QA" 같은 텍스트를 사용할 수 있습니다. 레이블을 적용한 후에는 기록 대화 상자에서 이 레이블과 연결된 모든 파일을 검색할 수 있습니다. 개별 파일에 레이블을 할당할 수도 있지만 대개 프로젝트 수준에서 레이블을 적용합니다. 프로젝트에 설명 문자열이 있는 레이블을 할당하면 해당 프로젝트의 모든 파일과 하위 프로젝트가 그 레이블을 사용합니다.
개발 주기의 어느 시점에서나 프로젝트에 레이블을 할당할 수 있습니다. 예를 들어 제품의 각 "릴리스"마다 알파, 베타 또는 최종 생산 코드에 관계없이 해당 시점에서 모든 프로젝트 항목에 레이블을 할당할 수 있습니다. 개발을 진행하다 베타 1.0의 소스 코드가 필요할 경우 그냥 가져오면 됩니다. 원하면 원본 파일에 아무런 영향을 미치지 않고 레이블의 이름을 바꿀 수 있습니다.
레이블을 만들려면 VSS Explorer 도구에서 레이블을 할당할 Project 폴더를 클릭하십시오. 메뉴에서 File | Label...을 클릭하면 그림 14와 같은 대화 상자가 나타납니다. 설명이 포함된 레이블 이름과 이 레이블의 사용 용도를 알려 주는 주석을 입력하고 OK를 클릭하여 레이블을 이 프로젝트와 이 프로젝트 아래의 모든 파일 및 하위 폴더에 적용합니다.
그림 14. VSS Explorer 도구를 사용하여 레이블 만들기
VSS Explorer에서 프로젝트를 다시 선택하고 마우스 오른쪽 단추로 클릭한 다음 Show History... 메뉴 항목을 클릭하여 History 대화 상자를 표시하면 그림 15와 같이 레이블이 표시됩니다.
.gif)
그림 15. VSS Explorer 의 History 대화 상자에서 적용한 여러 가지 레이블을 볼 수 있습니다.
기존 레이블에 파일 추가
버전에 레이블을 할당했는데 나중에 레이블이 할당된 버전에 포함되었어야 할 파일을 빠뜨린 것을 발견하는 경우도 있을 수 있습니다. 파일을 레이블의 일부분으로 추가하려면 파일을 프로젝트에 추가하기만 하면 됩니다. VSS Explorer에서 해당 파일을 클릭한 다음 File | Label...을 클릭하고 프로젝트에 할당한 것과 동일한 레이블을 할당합니다. 레이블을 기준으로 파일을 가져올 경우 레이블 이름이 동일하기 때문에 이 파일도 함께 가져옵니다. 레이블 이름을 정확히 입력했는지 확인하십시오.
레이블에 할당된 모든 파일 가져오기
특정 레이블이 할당된 파일을 모두 가져오려면 해당 파일에 대해 "가져오기(get)" 작업을 수행하면 됩니다. 즉, 특정 레이블 아래의 파일을 체크 아웃할 수는 없지만 가져올 수는 있습니다. 그러기 위해서는 VSS Explorer에서 내용을 가져올 프로젝트를 마우스 오른쪽 단추로 클릭하고 Show History...를 클릭합니다. Project History Options 대화 상자(그림 16 참고)가 나타나면 Labels Only 확인란을 선택하고 OK를 클릭합니다.
.gif)
그림 16. 프로젝트의 레이블 가져오기
선택한 프로젝트에 할당한 모든 레이블이 표시됩니다. 가져올 레이블을 클릭한 다음 화면(그림 15 참고) 오른쪽에서 Get을 클릭합니다. 그러면 이 레이블이 있는 모든 파일이 이 프로젝트에 할당된 작업 디렉터리로 복사됩니다. 이미 언급한 대로 레이블이 할당된 릴리스에서는 파일을 체크 아웃할 수 없습니다. 따라서 릴리스된 파일 집합은 아무도 무단으로 변경할 수 없습니다.
Visual Studio .NET에서 솔루션 가져오기
사용자가 빌드 중인 응용 프로그램에 대해 프로젝트 책임자가 초기 솔루션을 만들면 다른 개발자가 이 솔루션을 가져와서 각자의 컴퓨터에 설정할 수 있도록 해야 합니다. 이때 각 개발자가 자신의 컴퓨터에 가상 디렉터리를 다시 만들고 모든 파일을 올바른 위치로 가져왔는지 확인하게 할 필요는 없습니다. 다행히도 VSS 및 Visual Studio .NET에서는 이를 자동으로 처리합니다.
VSS와 통합된 Visual Studio .NET은 하드 드라이브에 적절한 폴더를 자동으로 만들고, 새 가상 디렉터리를 만들며, VSS에서 새 폴더로 파일을 자동 복사합니다. 항상 VSS가 아닌 Visual Studio .NET을 통해 이 프로세스를 수행해야 합니다. 그렇지 않으면 IIS를 수동으로 구성하고 VSS 데이터베이스에 대한 참조를 직접 설정해야 합니다.
다음 단계를 수행하려면 다른 컴퓨터를 사용하거나 앞에서 만든 가상 디렉터리를 지워야 합니다. Visual Studio .NET의 새 인스턴스를 엽니다. File | Source Control | Open from Source Control...을 클릭하면 그림 17과 같은 대화 상자가 나타납니다. 창에서 PortalVBVS 프로젝트를 클릭합니다. Create a new project in the Folder 입력란에 다른 폴더 이름을 입력하고 OK를 클릭합니다.
.gif)
그림 17. 새 폴더로 SourceSafe 프로젝트 가져오기
드라이브에 없는 폴더를 선택하면 폴더를 만들라는 메시지가 표시됩니다. 이 예제의 경우에는 폴더가 드라이버에 없어야 정상입니다. Yes All을 클릭하여 이 프로젝트에 필요한 모든 폴더를 만듭니다.
그림 18과 같이 이 프로젝트를 배치할 가상 디렉터리를 입력하는 대화 상자가 나타납니다.
.gif)
그림 18. 프로젝트에 가상 디렉터리 할당
SourceSafe 내의 프로젝트 및 솔루션 레이아웃 방법에 따라 열려는 솔루션 파일을 입력해야 할 수도 있습니다. 그럴 경우 대화 상자에서 .SLN 파일을 선택합니다. Portal 솔루션에서는 .SLN 파일이 분리된 자체 폴더 안에 있으므로 SourceSafe에서 아무런 대화 상자도 표시되지 않습니다.
다음으로는 이 가상 디렉터리를 만들 IIS의 위치를 입력하는 대화 상자가 나타납니다. 웹 서버 이름과 가상 디렉터리 이름을 입력하고 OK를 클릭합니다.
.gif)
그림 19. 웹 서버에 프로젝트 할당
이제 Visual Studio .NET에서 이 프로젝트의 모든 파일을 가져오기 시작합니다. 이 문서의 예제에서는 D:\PortalVBVS를 사용했습니다. 즉, 솔루션이 이 폴더에 저장된다는 의미입니다. 이 프로젝트의 다른 모든 파일은 기본 웹 사이트가 가리키는 폴더에 배치됩니다. 일반적으로 이 폴더는 c:\inetpub\wwwroot입니다. 이로써 프로젝트가 다른 개발자의 컴퓨터에 설정되었으며 사용 준비가 끝났습니다. 사이트의 시작 페이지를 선택하고 F5를 누르기만 하면 응용 프로그램이 실행됩니다. 이제 파일을 체크 아웃하여 작업하고 다시 체크 인할 수 있습니다. 이 모든 작업이 Visual Studio .NET 내에서 가능합니다.
결론
모든 개발자는 일상적인 작업에서 Visual SourceSafe를 사용해야 하며, 모든 개발 관리자는 팀에서 Visual SourceSafe를 사용하도록 해야 합니다. 개발자가 한 명뿐일 경우에도 이 도구를 효율적으로 사용하면 소스 코드를 다른 컴퓨터에 백업하고 소스 코드의 이전 버전으로 돌아갈 수 있습니다. VSS를 만들고 사용하는 것은 간단하고 쉽습니다. 사용 방법을 조금만 배우면 됩니다. 소스 코드 컨트롤이 뛰어나면 개발 프로세스가 향상되고 소프트웨어 구성 관리의 다양한 이점을 모두 활용할 수 있습니다.
BIO
Paul D. Sheriff는 SDLC 문서 및 아키텍처 프레임워크를 비롯한 .NET 컨설팅, 제품 및 서비스를 제공하는 PDSA, Inc.의 사장입니다(http://www.pdsa.com/ (US) 을 참고하십시오). 또한 남부 캘리포니아의 Microsoft 지역 책임자입니다. .NET 저서로는 ASP.NET Developer's Jumpstart(Addison-Wesley: 영문)와 PDSA 웹 사이트에서 구할 수 있는 여러 eBook이 있습니다. 전자 메일 주소는 PSheriff@pdsa.com입니다.
Michael Krasowski는 PDSA, Inc의 개발부 부사장입니다. 이전에는 The Boeing Company, Long Beach Division에서 선임 IT 관리자 직책을 역임했습니다. IT 분야에서 27년이 넘는 경험을 보유하고 있으며 캘리포니아 대학의 Irvine 사회 교육 과정에서 .NET에 대해 강의하고 있습니다. 전자 메일 주소는 Michaelk@pdsa.com입니다
최종 수정일: 2004년 2월 19일
출처 : MSDN
URL : http://msdn.microsoft.com/ko-kr/library/ms972977.aspx